A JBoss Project
Red HatThis site is no longer current and is for archival purposes only. All relevant content is moving to http://teiid.io

See http://teiid.io for the latest on Teiid and our cloud based offering. This site will be phased out entirely within a couple of major releases.
Teiid is a data virtualization system that allows applications to use data from multiple, heterogeneous data stores. |
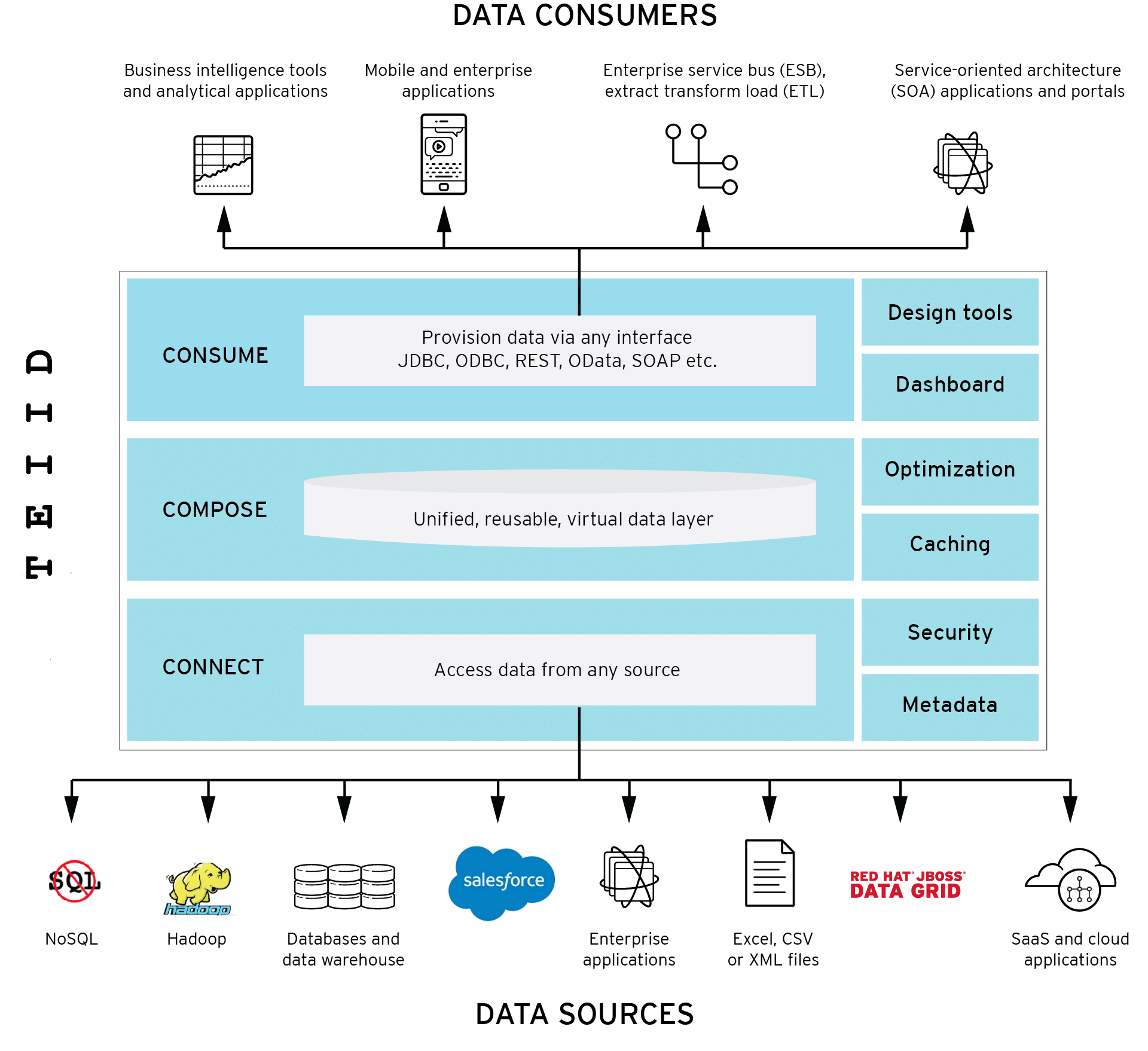 |
Teiid is comprised of tools, components and services for creating and executing bi-directional data access services.Through abstraction and federation, data is accessed and integrated in real-time across distributed data sources without copying or otherwise moving data from its system of record. |
Teiid Parts
| Query Engine | The heart of Teiid is a high-performance query engine that processes relational, XML, XQuery and procedural queries from federated datasources. Features include support for homogeneous schemas, heterogeneous schemas, transactions, and user defined functions. |
| Embedded | An easy-to-use JDBC Driver that can embed the Query Engine in any Java application. |
| Server | An enterprise ready, scalable, manageable, runtime for the Query Engine that runs inside JBoss AS that provides additional security, fault-tolerance, and administrative features. |
| Connectors | Teiid includes a rich set of Translators and Resource Adapters that enable access to a variety of sources, including most relational databases, web services, text files, and ldap. Need data from a different source? A custom translators and resource adaptors can easily be developed. |
| Tools |
|
Looking for a fully supported, certified Data Virtualization Platform?



- tei·id (TEE-id)
- adj. pertaining to a family of tropical American whip-tailed lizards noted for speed and agility.
- n. a set of open source enterprise information integration tools noted for their ability to rapidly create data services that can quickly adapt to changes in your IT environment.
Blog Posts
Useful links
